
Qué es un algoritmo
Entre otras muchas aportaciones, el matemático británico Alan Mathison Turing (1912—1954) formalizó el concepto «algoritmo»: un algoritmo es la sucesión de operaciones que permiten hallar la solución de un problema. Por tanto, un programa informático es un algoritmo o un conjunto de algoritmos.
Algoritmo: palabra que usan los programadores cuando no les apetece explicar lo que han hecho.
Quién es Alan Turing

Turing fue perseguido por su homosexualidad por el mismo gobierno al que había ayudado a ganar la II Guerra Mundial, pues resultó imprescindible para desencriptar los mensajes alemanes. En 1952 aceptó la castración química como alternativa a ir a la cárcel, lo que desencadenó una depresión que le llevó a suicidarse dos años después mediante la ingesta de una manzana envenenada con cianuro.
El test de Turing
Turing propuso una prueba para determinar si un software está dotado de inteligencia (artificial, claro está).
La prueba consiste en que un juez converse a través de una pantalla con un humano y con un software. Si el juez no es capaz de diferenciar cuándo habla con el software y cuándo con el humano, el software ha superado el test de Turing.
Desde 1990 se celebra el Premio Loebner, que premia al software que mejor pasa el test de Turing. La primera vez que se consiguió confundir a un juez fue en 2010, y en 2014 el robot Eugene Goostman convenció al 33 % de los miembros del jurado. El día que un software engañe a todos los miembros del jurado se concederá un premio de 100.000 dólares y se disolverá el premio.
El test de Turing sirve como excusa para que cualquier software con el que se pueda conversar mínimamente se considere inteligencia artificial. No obstante, en cuanto te cuente los métodos más sofisticados de inteligencia artificial coincidirás conmigo en la inutilidad de esta prueba.
Qué es la programación
Programar consiste en escribir instrucciones que indican a una computadora, paso a paso, cómo manipular ciertos datos de entrada para producir un resultado. Por ejemplo, la forma en la que está programada la aplicación de Google Maps debe ser algo así:
- Pide al usuario el destino deseado
- Accede al GPS del teléfono para obtener la ubicación del usuario
- Consulta la base de datos que contiene los nombres de todas las calles, su longitud y su volumen de tráfico a esta hora
- Teniendo en cuenta la longitud y tráfico en las calles entre la ubicación del usuario y el destino deseado, calcula el trayecto más rápido entre ambos puntos
- Muestra por pantalla, paso a paso, dicho trayecto
No creas que esto es una metáfora, los lenguajes de programación funcionan así, solo que las instrucciones se escriben en inglés. En esencia, los programadores que crearon Google Maps escribieron algo parecido a eso, aunque más extenso, pues el cálculo de la ruta más corta requiere un largo desarrollo matemático.
El destino, la ubicación y los nombres, longitud y tráfico de las calles son los datos de entrada. Un algoritmo calcula la ruta más corta entre el origen y el destino y muestra el resultado por pantalla. Todo software funciona obteniendo datos de entrada y manipulándolos para obtener un resultado.
Todo en la vida se puede predecir con matemáticas
Las instrucciones que manipulan los datos de entrada son operaciones matemáticas, porque todo en la vida se puede averiguar con funciones matemáticas. Y cuando digo todo, quiero decir todo: el trayecto más corto entre dos puntos, si dos coches tendrán un accidente, cuántas veces te casarás y con quién, cuál será el próximo número ganador de la lotería o a qué edad morirás y dónde. Aun así, la vida no es determinista porque casi nunca tenemos todos los datos de entrada, o si los tenemos, no sabemos cómo usarlos. Es para este último caso, cuando tenemos la información que necesitamos pero nuestro limitado cerebro no sabe qué hacer con ella, cuando la inteligencia artificial viene al rescate.
Por ejemplo, la inteligencia artificial es capaz de analizar una tomografía y predecir, con más precisión que cualquier médico, si el paciente tiene cáncer. Si esto te suena a ciencia ficción, agárrate: resulta que no entendemos del todo por qué funciona.
La inteligencia artificial se basa en un algoritmo «comodín», un algoritmo que, jugando con el valor de sus parámetros, soluciona casi cualquier problema siempre y cuando contemos con los datos de entrada necesarios y la potencia computacional suficiente. Más de esto en un instante.
Cómo funciona un chatbot
Un chatbot es un software capaz de conversar por escrito con un humano. Viendo cómo funciona Google Maps resulta fácil entender cuál es la forma más rudimentaria de programar un chatbot:
- Crea una enorme base de datos de palabras y expresiones
- Asocia cada término o expresión a una respuesta
- Cuando el usuario introduzca una frase, busca en la base de datos la expresión más similar y muestra la respuesta asociada
Si incluyes millones de palabras y expresiones tu chatbot superará el test de Turing. ¿Inteligencia? Más bien memoria.
Podemos sofisticar el software, por ejemplo, conjugando el verbo de las respuestas para que coincida con el tiempo empleado por el usuario, personalizar el género, responder con una pregunta si no encontramos similitudes en la base de datos, usar una lista de palabras negativas que en caso de estar incluidas en el mensaje del usuario reduzcan el número de posibles respuestas… pero siempre que programemos como he explicado hasta ahora, nuestro chatbot funcionará de forma predecible, y eso no tiene nada que ver con lo que entendemos como inteligencia.
Qué es el machine learning
Te voy a contar cómo crear software que mejore con el paso del tiempo y por sí solo, que es en lo que consiste el machine learning o «aprendizaje automático».
Imagina que queremos construir un software capaz de aprender a jugar al Tetris. Para ello, el programador escribe un algoritmo muy sencillo:
- Puedes pulsar las teclas «derecha», «izquierda» y «rotar pieza» en cualquier momento
- El objetivo es obtener la máxima puntuación
El software empieza a pulsar teclas sin ningún criterio y a observar la puntuación en cada instante. Como la memoria de una computadora es infinita, después de unas cuantas miles o millones de partidas el software recordará qué tecla produce el mejor resultado en cada circunstancia, derrotando así a cualquier humano al que se enfrente.
Aquí tampoco hay inteligencia, pero sí aprendizaje. Aprendizaje a base de prueba y error a la velocidad de la luz combinado con una memoria prodigiosa.
Regresión
Cambio de tema. Partiendo de una nube de puntos podemos dibujar la gráfica que mejor se ajusta a dichos puntos, por ejemplo:

La regresión nos permite predecir resultados. Sabiendo el número de goles marcados por un equipo podemos estimar su clasificación. Veamos si funciona.
La función matemática de la regresión lineal anterior es: Clasificación = –0,2753 × Goles + 21,705
Ahora busquemos los datos de la siguiente temporada (86–87), escojamos un equipo al azar, consultemos cuántos goles marcó y veamos si podemos adivinar en qué posición acabó.
Veo que en la temporada 86–87 la Real Sociedad marcó 59 goles, y nuestra regresión linear nos dice que ese número de goles corresponde con la posición 5,4623:
Clasificación = –0,2753 × Goles + 21,705 = –0,2753 × 59 + 21,705 = 5,4623
Comprobando los datos vemos que la Real Sociedad acabo en la posición… ¡5! Nada mal, aunque no es perfecto (nuestra predicción tiene decimales), y es que la gráfica anterior tampoco lo era, pues no pasaba por encima de todos los puntos, solo se acercaba. Si incorporamos más variables (como los goles en contra) seguramente podamos dibujar una gráfica más compleja que se ajuste mejor a la nube de puntos, es decir, que nos permita hacer predicciones más precisas.
Podemos incluso cuantificar la imperfección de una regresión midiendo la diferencia media entre la línea y cada uno de los puntos. A esta medida le llamamos error. A menor error, mejor ajuste y, por tanto, mejores predicciones.
Antes decía que cualquier cosa se puede expresar con una función matemática, solo es necesario tener en cuenta todas las variables que influyen. Imagina que queremos averiguar cuánto dinero vas a ganar a lo largo de tu vida. Primero tendríamos que identificar qué variables afectan al resultado: estudios, lugar y año de nacimiento, estado de salud, cociente intelectual… y unas cuantas miles más. Si pudiéramos identificar todas, cuantificarlas y obtener los datos de millones de personas, podríamos deducir la función matemática que diga cuánto dinero tú, o cualquier persona, va a ganar a lo largo de su vida.
Averiguar qué variables influyen en la cantidad de dinero que ganarás es difícil, encontrar el peso que tiene cada una, todavía más. Porque, piénsalo, aunque tanto el lugar donde naces como tu cociente intelectual influyen en tus ingresos, ambos factores no tienen el mismo peso en el resultado.
«Lo que llamamos suerte no es más que el conjunto de datos que desconocemos».
Imagina lo difícil que es modelar una función matemática así. Miles o millones de variables, cada una con un peso diferente. ¿Se te ocurre cómo solucionar este problema? Como si de una partida de Tetris se tratara, el machine learning puede, a base de prueba y error, encontrar el peso de las variables con el que se obtiene el menor error.
Qué es y cómo funciona una red neuronal
Llamamos «red neuronal» al procedimiento que explico a continuación porque su diseño se inspiró –de manera muy libre– en cómo creemos que funcionan las neuronas.
Sea como fuere, las redes neuronales están constituidas por entidades a las que llamamos neuronas. Las neuronas reciben datos de entrada de otras neuronas, los procesan, y producen datos de salida que envian a otras neuronas, y así, con tantos niveles o capas como deseemos, hasta que la información llega a las últimas neuronas de la red, que muestran el resultado que buscamos.
 Como ya adelantaba, cada conexión entre dos neuronas tiene un peso distinto. Al peso le llamamos w, del inglés weight.
Como ya adelantaba, cada conexión entre dos neuronas tiene un peso distinto. Al peso le llamamos w, del inglés weight.
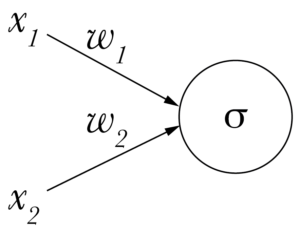
Los datos que llegan a cada neurona se pasan por una función matemática que se llama sigmoide y es así:
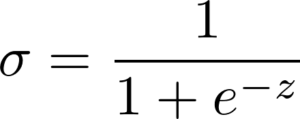
donde
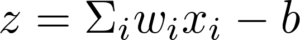
El valor de b o sesgo, del inglés bias, también es un valor distinto en cada neurona, y también tenemos que encontrar su valor óptimo para que la red funcione. Esta es la representación de un sigmoide:
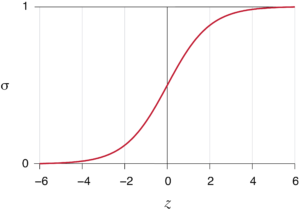
Siempre que produzca un resultado entre 0 y 1 la función de la neurona puede ser otra, aunque el sigmoide tiene la ventaja de que pequeños cambios en b producen pequeños cambios en σ, lo que facilita encontrar su valor más adecuado.
Si lo piensas, una red neuronal es como una gran función de regresión adaptable a cualquier circunstancia. Cada neurona por la que pasan datos es un factor de esa función. Con los pesos de las conexiones y los valores de b hay factores que ganan importancia y otros que incluso llegan a anularse.
Volvamos al ejemplo de la detección de cáncer en tomografías. ¿Qué datos de entrada tenemos en este caso? Una imagen. ¿Y qué es una imagen? Una montón de puntitos de distintos colores, los píxeles. Y cada color que se puede mostrar en una pantalla tiene un número asignado.
Es decir, para una imagen de 1.024 píxeles de ancho y 768 píxeles de alto, tenemos 786.432 datos de entrada, consistendo cada dato en el valor del color de cada píxel.
Y los datos de salida serán dos neuronas, cada una de las cuales puede adquirir un valor entre 0 y 1. Si la red neuronal considera que hay cáncer, el valor de la primera neurona será próximo a 1 y el de la segunda próximo a 0. Al revés si la red neuronal considera que no hay cáncer.
Igual que ocurría con los equipos de fútbol, aquí el resultado tampoco va a ser perfecto. Los valores de las neuronas de salida nunca serán un 0 y un 1 absoluto, siempre habrá un margen de error. Un error que, como hemos visto antes, podemos medir. Solo queda elegir el número de neuronas, asignar los pesos de cada conexión y asignar los valores b de tal forma que ese error sea el menor posible.
De nuevo se trata de probar valores hasta dar con el mejor resultado. De nuevo machine learning. De nuevo es igual que aprender a jugar a un videojuego, solo que, ahora, en lugar de máxima puntuación buscamos mínimo error.
A este proceso se le llama «entrenar la red» y para hacerlo necesitamos un set de datos cuyo resultado conozcamos. Como imaginarás, entrenar una red requiere muchos datos y mucho, pero que mucho tiempo, aunque existen técnicas para que el proceso de prueba y error sea más eficiente que depender enteramente del azar.
Qué es el deep learning
La expresión deep learning, que significa «aprendizaje profundo», hace referencia a que una red neuronal está formada por capas intermedias a las que llamamos capas ocultas o invisibles (hidden layers en inglés).
¿Para qué sirve la inteligencia artificial?
La inteligencia artificial es ideal para resolver tareas difíciles de procedimentar, es decir, tareas en las que es difícil establecer una secuencia rígida de pasos que lleven a un resultado. Como ocurre con la detección de cáncer en una tomografía. Sin embargo, más interesante aun es que la inteligencia artificial puede encontrar soluciones más óptimas que las que conocemos. Soluciones que incluso no entendamos.
Otras situaciones con similar problemática son: diagnóstico de enfermedades a partir de síntomas, digitalización de texto manuscrito, reconocimiento de voz, reconocimiento de imágenes, detección de fraude con tarjetas de crédito, ubicación óptima de semáforos y señales en ciudades, inversión en bolsa, contratación de empleados, planificación de campañas publicitarias, composición musical, traducción, detección temprana de averías en máquinas o filtrado de spam.
No obstante, no te emociones. Mientras algunas de estas situaciones ya se solucionan con inteligencia artificial, para otras nunca encontraremos el modelo que las resuelve o la potencia computacional que necesitamos es mayor de la que disponemos.
Bibliografía
- Configura una red neuronal a golpe de ratón con Tensor Flow.
- Si estás muy motivado, el libro online Deep Learning es el lugar al que acudir.
Si quieres recibir los artículos que no escribo por aquí, susríbete al newsletter: